

本文作家邹德誉,香港汉文大学运筹帷幄机科学与工程系博士生,本科毕业于中国科学时候大学。辩论标的为谣言语模子智能体、强化学习与主动推理,温文模子在信息不完备的多轮交互中如何主动获取、更新并哄骗信念。关系责任发表于 ICLR 2026 Oral 与 ICML 2026。
跟着谣言语模子渐渐从「单轮问答」走向「真实环境中的捏续交互」,LLM agents 正在被用于越来越复杂的 agentic applications:deep research、coding、computer use、customer service、medical inquiry、troubleshooting 等等。这些任务和传统问答最大的不同在于:任务所需的信息往往不是一脱手就完整给出的。Agent 必须在不笃定情状下主动采纳活动,举例发问、搜索、调用器具、查验反映,并在多轮交互中连接更新我方对任务情状的领路。
这类才能不错笼统为 active reasoning:在信息不完备的环境中,agent 不单是 “回答问题”,而是需要主动获取新信息,并把新信息实在整合进后续决策和推理中。
根据过往在许多推理任务上的生效,强化学习似乎应该很适合考试这类才能。只须终末任务生效就给正奖励,失败就不给奖励,模子不就应该渐渐学会更好的交互政策吗?
但事情并莫得这样简易。与此前 T3 (Reducing Belief Deviation in Reinforcement Learning for Active Reasoning of LLM agents | ICLR-2026 Oral)对多轮推理中 belief deviation 和 belief-trapped trajectory 的分析相呼应,香港汉文大学、加州大学圣地亚哥分校、佐治亚理工学院、字节进步的辩论者进一步发现发现,在 active reasoning 场景中,outcome-based RL 并不一定会自然考试出更善于交互的 agent。违犯,模子可能投入一种低信息量的考试模式:它反复实践无效操作,过早依赖开动判断,忽略用户或环境复返的新根据;以致在最终 reward 有所进步时,背后的步履也未必实在变得更会主动获取和使用信息。
若是说 T3 更温文 agent 在多轮交互中如何渐渐偏离正确 belief,那么这篇论文《On Information Self-Locking in Reinforcement Learning for Active Reasoning of LLM Agents》系统分析了这一形势背后的原因:在 active reasoning 中,agent 的表露同期依赖于两个相互耦合的才能:一方面是遴荐什么动作来获取信息,另一方面是如何把获取到的信息整合进后续判断。outcome reward 很难自动为这两个相互依赖的重要提供清晰 credit:面前者无法带来灵验反映,后者就穷乏可学习的根据;而当后者无法正确领受反映时,前者的价值又很难通过最终 reward 得到正确 credit。
辩论者将这种考试失败机制称为:
Information Self-Locking,信息自锁。
基于这一不雅察,作家进一步建议了一个简易而灵验的纪律:AREW(Action-Selection & Belief-Tracking Advantage Reweighting),通过轻量的标的性反映再行分拨 trajectory 里面的 credit,从而缓解 information self-locking。
论文已被 ICML 2026 接受。

论文标题:On Information Self-Locking in Reinforcement Learning for Active Reasoning of LLM Agents
款式代码:https://github.com/unimpor/T3
论文磋磨:https://arxiv.org/abs/2603.12109
绪论:为什么 RL 考试出来的 agent 照旧不会主动推理?
在好多 LLM agent 任务中,模子并不可一脱手就看到完整谜底。它必须通过多轮交互渐渐面对真实任务情状。
比如:
在医疗问诊中,agent 需要主动盘问重要症状,而不是重迭问频频的问题;
在用户偏好料到中,agent 需要运筹帷幄有别离度的问题,渐渐识别用户实在的偏好;
在客服场景中,agent 需要决定什么期间发音书、什么期间调用器具、什么期间指点用户完成某些操作。
这些任务有一个共同结构:agent 的表露同期取决于两件事。
第一,它要知谈下一步该问什么、查什么、调用什么器具。作家称为 Action Selection(AS)。
第二,它要能把得到的新反映领受进我方的里面领路,实在更新对任务情状的判断。作家称为 Belief Tracking(BT)。
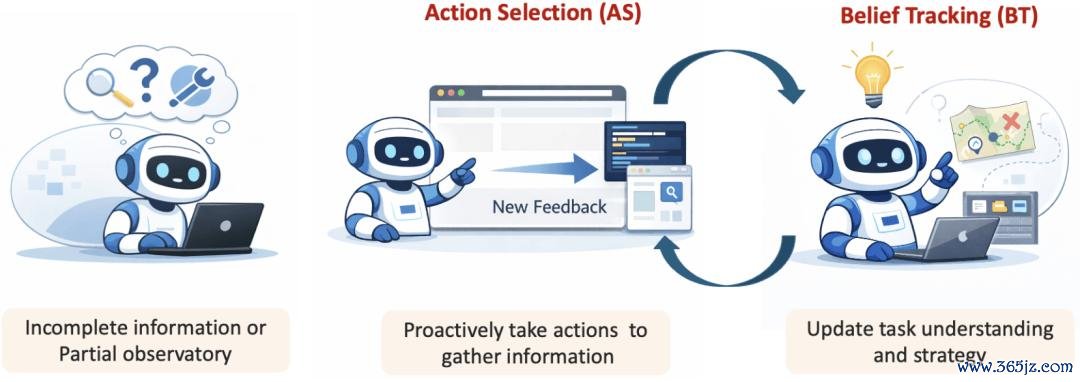
若是 AS 很弱,agent 就拿不到有用信息;若是 BT 很弱,即使拿到了有用信息,模子也不会用。
更重要的是,这两者不是独处的,而是强耦合的:
好的活动只须在反映被正确使用时,才会在最终 reward 中体现价值;好的 belief update 又依赖于前边活动带来了有余有信息量的反映。
这就带来了 active reasoning 中一个尽头藏匿的 credit assignment 问题:outcome reward 只在终末出现,它很难判断到底是 “问得不好”,照旧 “问到了但没领受好”。
论文第一页的图给出了这一机制的举座直观。
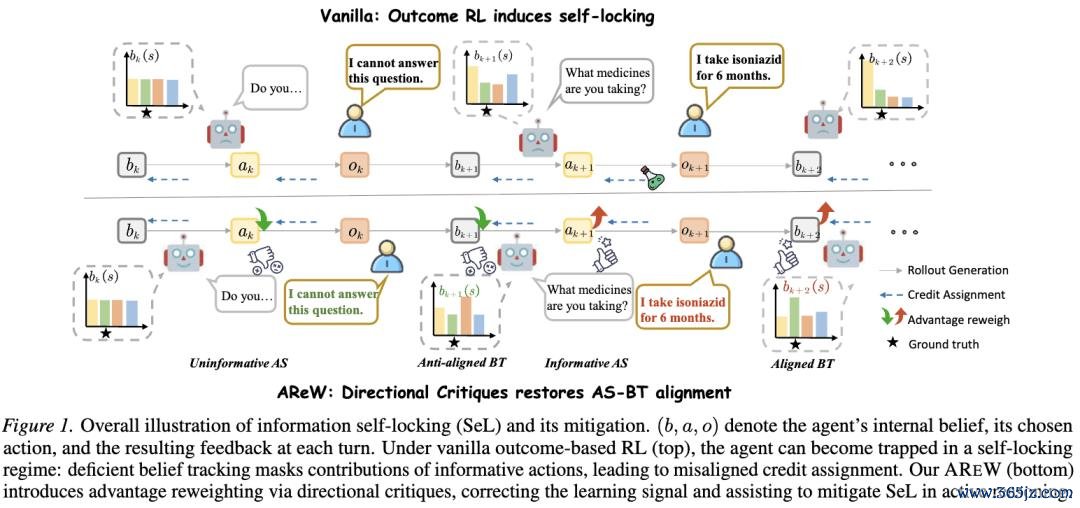
图:原文 Figure 1。Vanilla outcome RL 下,agent 可能投入 self-locking:informative action 的价值被 weak BT 隐敝,导致 credit assignment 错位;AREW 通过 directional critiques 再行分拨 trajectory 里面 credit,使 AS 和 BT 再行对王人。
Information Self-Locking:考试信号被 “锁住”
作家领先发现了一个反直观形势。
在 outcome-based RL 中,reward 可能确乎高涨了,但这并不料味着模子实在学会了主动获取信息。为了解耦不雅察这小数,论文先在两个可控的 active reasoning 任务中作念分析:Preference Estimation 要求 agent 通过比较问题渐渐料到用户荫藏偏好,MediQ 则要求 agent 通干涉诊病东谈主问题渐渐识别正确会诊。二者都需要 agent 一边主动获取根据,一边更新对荫藏任务情状的判断,因此很适合用来不雅察 AS 和 BT 的考试动态。
论文在这两类任务中追踪了三个量:
Final reward:最终任务表露;
AS proxy:agent 的活动是否带来有信息量的反映;
BT proxy:agent 是否把反映正确领受进 belief。
收尾高傲,reward 不错作念有限的高涨,但 AS 和 BT 并莫得同步进步。也即是说,模子名义上变强了,但它并莫得实在更会 “获取信息” 和 “使用信息”。
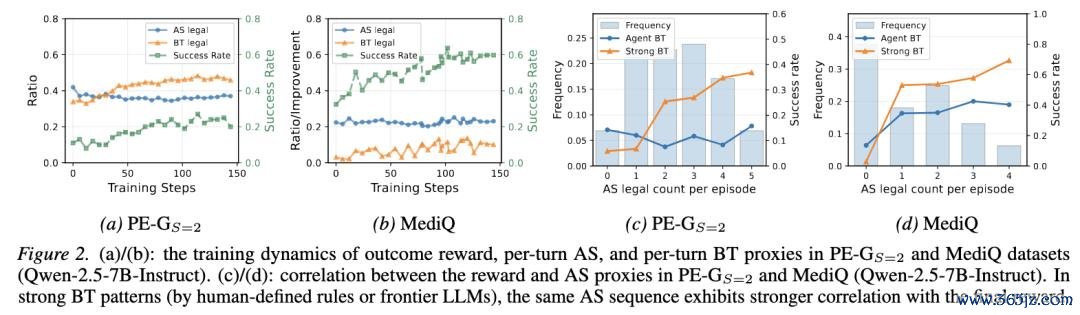
图:原文 Figure 2。左半部分展示考试经由中 reward、AS、BT 的变化:蓝线暗示 agent 作念出有信息量活动的比例,橙线暗示 agent 是否灵验领受反映并更新 belief,绿线暗示最终任务生着力。不错看到,即使生着力随考试有一些有限的高涨,AS 和 BT 也可能停滞以致退化。右半部分进一步固定换取的 action-selection 序列:横轴暗示一条轨迹中有若干次有信息量的活动,浅蓝色柱子暗示这类轨迹出现的频率;蓝线暗示由 agent 自身 BT 处理这些反映时的生着力,橙线暗示由 stronger BT 处理换取反映时的生着力。收尾高傲,只须当 BT 有余强时,informative AS 才会和最终 reward 变成更强正关系。
这张图的右半部分揭示了 AREW 的中枢 insight:
Weak BT 会遮盖 informative AS 的孝顺。
假定 agent 建议了一个很有价值的问题,环境也复返了重要根据。但若是模子莫得把这条根据领受进后续推理,最终谜底仍然错了。此时,outcome reward 会告诉 RL:“这条 trajectory 失败了。”
问题在于,RL 并不知谈失败的原因是 belief update 作念得差,而不是 action selection 作念得差。于是,阿谁本来很有价值的问题也可能得不到正向 credit。
反过来亦然雷同。
若是 AS 变得保守,模子老是问一些低信息量的问题,BT 就拿不到有价值的反映。莫得有余信息流,belief tracking 也很难学好。久而久之,RL 可能反而饱读吹模子依赖开动判断或非交互式 shortcut,而不是确认哄骗交互反映(详见谅文 Section 2.3 observation 3 | Fig. 6a)。
这即是 information self-locking:
AS 弱导致 BT 没根据可学;BT 弱导致 AS 的价值无法被 reward 识别。二者相互放置,使模子卡在低信息量考试区域。
从 Sef-Locking 看 active reasoning 的考试瓶颈
前边提到,论文将 active reasoning 中的 agent 步履解析为两个相互瓜代的经由:
Action Selection(AS):根据面前 belief 遴荐下一步环境交互动作,举例发问、搜索、调用器具;
Belief Tracking(BT):根据新反映更新里面任务领路,并决定后续如何活动。
这个解析指出 active reasoning 的难点不单是 sparse reward,而是 sparse outcome reward 下两个才能的耦合学习失败。
普通 outcome RL 只看到最终成败,很难把 reward 正确分拨给 trajectory 中不同的 AS 和 BT 决策。收尾是:
若是 BT 差,好的 AS 活动也无法鼎新为高 reward;
若是 AS 差,BT 莫得有余信息不错领受;
若是二者都处于低水平,梯度信号会同期变弱;
模子可能恒久停留在低信息量区域,难以靠 outcome reward 自行逃离。
论文在表面部分把这个区域现象化为 self-locking regime:AS informativeness 低,同期 BT capability 也低。在这个区域中,outcome-gradient 对 AS 和 BT 的进步信号都会被面前才能水平放置,因此考试动态很难自然逃出。
为了更直不雅地讲解这小数,论文 appendix 给出了一个二维相图:横轴暗示 AS informativeness,纵轴暗示 BT capability。
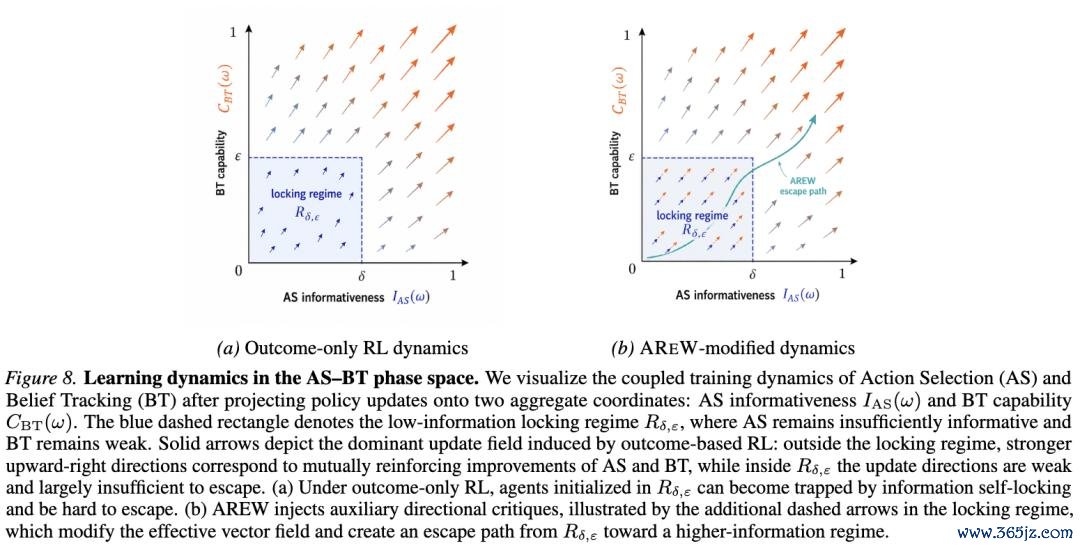
图:原文 Figure 8。AS-BT phase space 中的 learning dynamics。左图暗示 outcome-only RL:在低 AS、低 BT 的 locking regime 内,更新标的很弱,agent 难以逃离;右图暗示 AREW:directional critiques 在 locking regime 内引入极端更新标的,为模子创造逃离低信息量区域的旅途。这张图笼统了 AREW 的表面直观:作家不需要透澈重写 RL,也不需要精准 dense reward;只需要在 AS/BT 的重要局部决策上提供一些标的性信号,就不错编削低信息量区域内的 effective update field。
AREW:用 weak directional critiques 再行分拨 trajectory 里面 credit
既然 SeL 的中枢问题在于 outcome reward 难以在 AS 和 BT 之间提供清晰的学习信号,一个平直的决策,是为每个中间决策都运筹帷幄精准的 dense supervision:举例准确判断某个问题到底孝顺了若干信息,或者某次 belief update 到底应当取得若干中间奖励。关联词,在长程 agentic tasks 中,这类 calibrated intermediate reward 往往不可浮松取得。
红运的是,agentic active reasoning 场景频繁会自然清爽一些更粗粒度、但更容易获取的标的性会诊信号:举例,一个 action 是否让环境或用户复返了新的有用根据;一次 belief update 是否把新不雅察朝着更接近真实任务情状的标的领受进去。
AREW 的起点恰是哄骗这些 uncalibrated directional signals。它并不试图为每一步构造精准的中间奖励,也不需要考试极端的 dense reward model,而是把这些标的性信号行为 weak directional critiques,注入到 policy-gradient 更新中,对 trajectory 里面的 stepwise advantage 进行再行分拨。
换句话说,AREW 保留原来的 outcome reward,只是在 actor update 时把更多 credit 分拨给被正向 critique 的 AS/BT 决策,并减轻被负向 critique 的决策。通过这种 reward-preserving 的 credit reallocation,AREW 在 SeL regime 中再行提供非退化的局部学习信号,使 AS 和 BT 有契机共同改善并逃离低信息量考试区域。
在兑现上,AREW 将一条 trajectory 中被正向 critique 的智商采集记为 positive steps,被负向 critique 的智商采集记为 negative steps。然后构造一个 intra-trajectory likelihood margin:增多 positive steps 的 log-probability,相对裁汰 negative steps 的 log-probability。
经过推导(详见谅文 Section 4.2),最终落实到 policy gradient 上,即是一个尽头轻量的 advantage reweighting:
对原来每一步的 advantage 加上一个由 critique 决定的局部修正项。
开元棋牌2026世界杯中国官网入口直不雅来说,AG真人国际中国官网登录入口AREW 作念的是:
不编削最终 outcome reward;
不编削 critic target;
不重写 PPO / GRPO / GSPO 的中枢框架;
只是在 actor update 时,把 trajectory 里面的 credit 从负向智商再行分拨给正向智商。
这使得 AREW 具有很强的可集成性:它不错行为一个表层 credit assignment 修正机制,插入现存 outcome-based RL pipeline。
更进犯的是,AREW 不要求 critique 无缺。表面分析(原文 proposition 4.1)标明,只须 directional critiques 的 weighted accuracy 好于随即,就不错提供有用的一阶修订信号。背面的实验也考证了这小数:即使 critique 有噪声,AREW 仍然频繁优于 vanilla RL。
实验建筑:4 个交互边界,9 个 active reasoning 任务 / 建筑
论文在多个 agentic active reasoning 场景中系统评估 AREW。
举座包括 4 个交互边界:
1. Preference Estimation
Agent 需要通过多轮 pairwise comparison 渐渐料到用户荫藏偏好向量。该边界包含 PE-G 和 PE-F 不同建筑。AREW 在这里领受的 AS 信号尽头直不雅:若是两部被比较的 item 在不同属性维度上存在 trade-off,而不是一方在通盘维度上都昭彰占优,那么这个 comparison 更可能带来有信息量的偏好反映;BT 信号则看 agent 更新后的偏好料到是否比上一轮更接近真实偏好向量。
2. Medical Diagnosis
在 MediQ 中,agent 需要基于 clinical vignette 和候选假定,主动盘问病东谈主会诊关系问题,并渐渐提高正确会诊 的 belief。AREW 的 AS 信号来自 patient feedback 是否确实提供了新的会诊信息;BT 信号则查验模子是否根据灵验反映合理更新了不同会诊假定的置信度,举例是否让正确假定相对其他候选更占优,或者在无信息反映下保捏 belief 不被失误扰动。
3. Troubleshooting
在 FloDial 中,agent 需要通过 yes/no diagnostic questions 排查用户问题,并从候选讲解或搞定决策中识别正确项。AREW 在这里把用户反映行为轻量标的性信号:若是问题射中了可会诊信息并得到灵验 Yes/No 反映,就评释该 action 更有价值;若是只得到 Unknown,则评释该问题莫得匹配到灵验会诊陈迹。BT 侧则进一步查验 agent 是否在取得灵验反映后提高了正确故障候选的置信度;若是反映是 Unknown,则更但愿 belief 保捏踏实,而不是造谣漂移。
4. Customer Service / Tool Use
在 tau2-bench-Telecom 中,agent 需要通过多轮对话和器具调用完成真实感更强的 telecom customer-service 任务。AREW 的建筑在本文背面会被单独提到。
在前三个边界中,论文评估了 7 个 active reasoning tasks;在 tau2-bench 上进一步评估 solo setting 和 standard dual-control setting,整个变成 9 个任务 / 建筑。通盘任务都只提供终端监督。
主要模子包括 Qwen2.5-7B-Instruct 和 LLaMA-3.1-8B-Instruct。RL 算法包括 PPO,并进一步膨胀到 GRPO 和 GSPO。
主收尾:AREW 在简直通盘建筑下踏实优于 vanilla PPO
论文领先在前三个边界的 7 个任务上论说最终平均 outcome reward。
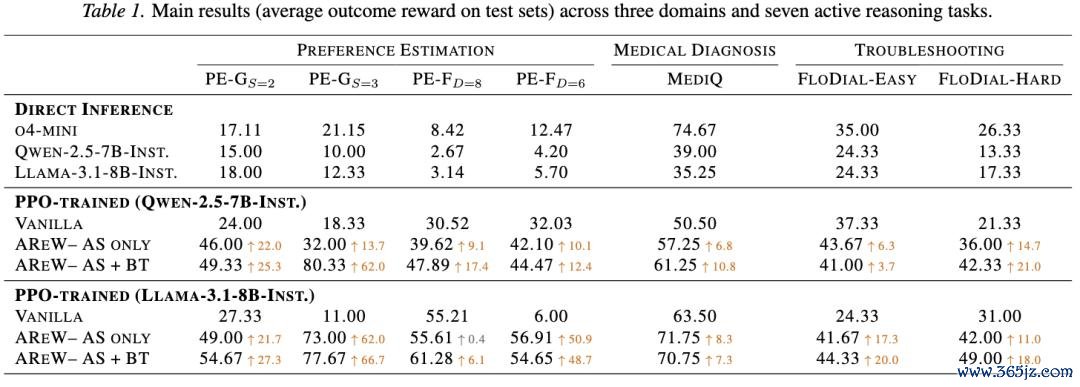
表:原文 Table 1。AREW 在 Preference Estimation、Medical Diagnosis、Troubleshooting 三个边界的 7 个 agentic active reasoning tasks 上,与 direct inference 和 vanilla PPO 进行比较。
这里,AREW-AS only 暗示仅使用 action-selection 侧的 directional critiques 来重加权动作决策的 advantage,而 AREW-AS+BT 则同期使用 action-selection 和 belief-tracking 两侧的 critiques,对 “获取信息” 和 “领受信息” 两个重要的 credit 进行斡旋修正。
主收尾尽头清晰:
在 28 个 PPO 评估建筑中,AREW 在 27 个建筑中显耀优于 vanilla PPO。
这些收尾评释,AREW 的收益并不是某个模子或某个数据集上的或然形势,而是在不同模子族和不同 active reasoning 任务中都能踏实施展作用。
考试动态:AREW 不单是提高最终分数,也编削了学习经由
除了最终收尾,论文还展示了考试经由中的 reward dynamics。
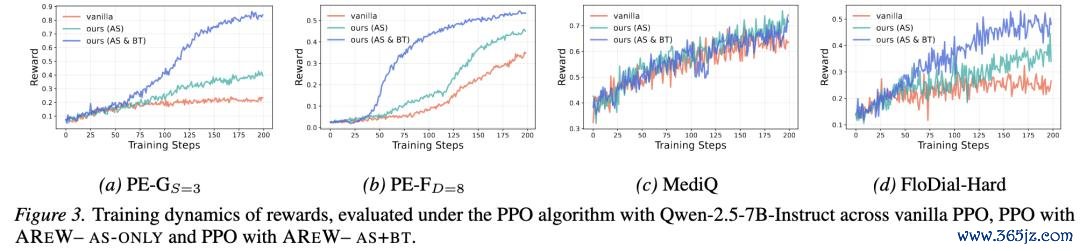
图:原文 Figure 3。Qwen2.5-7B-Instruct 上,vanilla PPO、AREW-AS only、AREW-AS+BT 在 PE、MediQ、FloDial-Hard 上的 reward training dynamics。
这张图不错看到三类典型形势。
在一些任务中,vanilla PPO 简直无法捏续进步 reward;而 AREW 不错昭彰冲破这种停滞,并捏续提高 performance。
在一些 vanilla PPO 本来也能纯粹进步的任务中,AREW 仍然表表露更快的拘谨速率和更高的最终 reward。
即使某些情况下 reward curve 看起来差距莫得那么大,AREW 也会在 AS 和 BT 步履层面带来更清晰的修订。也即是说,AREW 不单是 “刷高分”,而是在编削模子获取和使用信息的方式。
AS/BT 步履分析:AREW 确实让 agent 更会获取和领受信息
为了考证 AREW 的修订是否来自 active reasoning 才能自身,论文进一步分析了 AS 和 BT proxy。
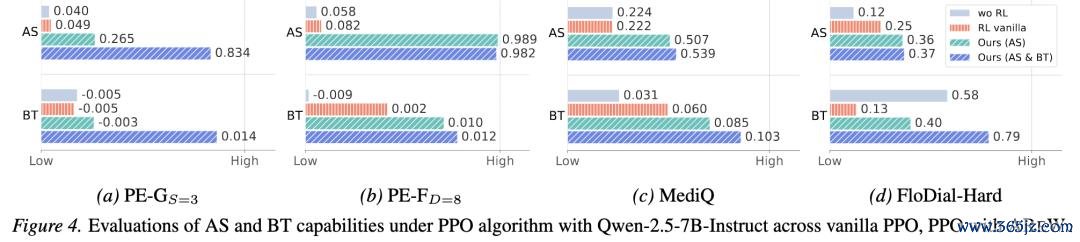
图:原文 Figure 4。AREW 对 AS 和 BT capability proxies 的影响。
这张图最值得介意的场所,不单是 AREW-AS+BT 恶果最佳,还有:AREW-AS only 也曾不错同期改善 AS 和 BT。
名义上看,AS-only 只对 action-selection 侧进行 advantage reweighting,也即是只饱读吹模子遴荐更有信息量的动作,并莫得平直给 belief-tracking 决策极端加 credit。但实验收尾高傲,只是改善信息获取,BT 也会随之变好。
这刚巧评释 AS 和 BT 并不是两个相互独处的才能。更好的 AS 会编削 agent 后续看到的 observation stream:当环境或用户复返的反映更有信息量,belief tracking 就更容易从这些反映中学习和更新。换句话说,即使莫得平直优化 BT,只须 AS 提供了更高质地的信息流,BT 的学习条目也会被改善。
自然,AS-only 并不可透澈替代 BT-side correction。Figure 4 中,AREW-AS+BT 在大宗情况下会进一步进步 BT proxy,评释当模子不仅被饱读吹 “获取更有用的信息”,也被饱读吹 “把这些信息正确领受进 belief” 时,AS 和 BT 更容易变成正向轮回。
因此,AREW 的收益不是简易来自某个单点模块的增强,而是来自对 AS-BT coupling 的打扰。只修正 AS 也曾大约带动 BT,而同期修正 AS 和 BT 则不错更充分地冲破 information self-locking。
不同 RL 算法灵验性
一个自然问题是:AREW 是否只是对 PPO 有用?
论文进一步在 GRPO 和 GSPO 上作念了实验。收尾高傲,即使使用 group-based RL variants,self-locking 仍然可能存在;只是增多 rollout 采样 并不可从根柢上搞定 AS/BT 的耦合 credit assignment 问题。而 AREW 在 GRPO 和 GSPO 下也能进步 final performance、AS 和 BT proxies。

图:原文 Figure 6 (b) (c)。
真场景应用 customer-service agent:tau2-bench 上的收尾
除了 controlled domains,论文还在更复杂的 tau2-bench-Telecom 上评估 AREW。
tau2-bench 的挑战在于,agent 不单是问答,还需要在多轮 customer-service 场景中进行器具调用、与用户和谐,并完成真实感更强的奇迹任务。
论文领先探究 no-user solo setting。在这个 setting 中,Qwen2.5-7B agent 平直限制任务搞定经由。AREW 使用 benchmark 自带的信号构造 critiques:
负向 critique 主要来自运行经由中的昭彰失败,举例器具调用现象失误、器具实践失败、重迭实践换取动作等;
正向 critique 则来自任务评估器提供的进展信号,举例面前轨迹是否新完成了某个预期动作,或是否比上一阶段更接近任务完成。
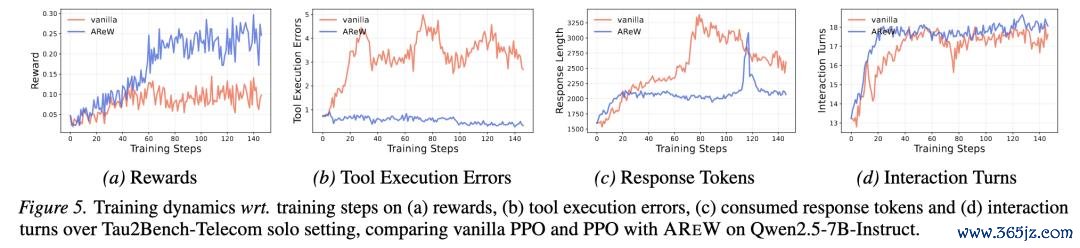
图:原文 Figure 5。Tau2Bench-Telecom solo setting 中,AREW 进步 reward,同期显耀减少 tool execution errors;何况这种进步不是靠更长回复或更多交互轮数换来的。
Figure 5 展示了一个实用收尾:AREW 不单是提高 reward,还显耀减少 tool execution errors,同期 response tokens 更少,interaction turns 基本可比。这评释 AREW 的收益不是简易来自 “说更多” 或 “多试几轮”,而是来自更灵验的 credit assignment。
论文进一步探究 standard dual-control setting。在这个 setting 中,Qwen2.5-14B agent 需要和 GPT-4o-simulated user 和谐。这里存在一个更复杂的 credit assignment 问题:任务进展可能来自 agent 我正大确使用器具,也可能来自 agent 指点用户完成 user-side repair actions。
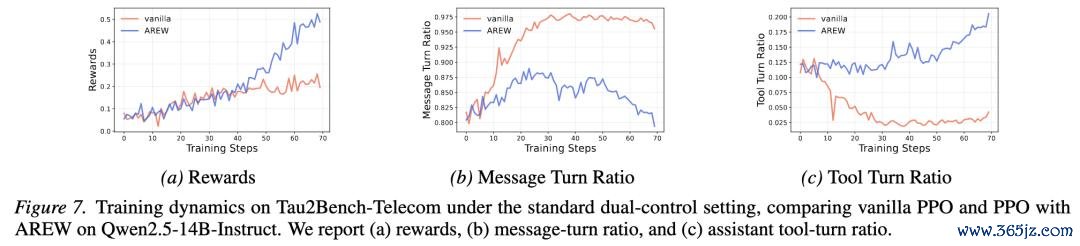
图:原文 Figure 7。Tau2Bench-Telecom standard dual-control setting 中,AREW 比拟 vanilla PPO 将 reward 从约 0.20 进步到约 0.50,同期减少对 user-side operation shortcut 的依赖,并保捏更多 assistant-side tool-use 步履。
在 vanilla PPO 中,模子容易走向一种 shortcut:更多依赖用户侧操作来完成部分任务,而 assistant 我方的 tool-use 步履反而下落。这自然能搞定一部分样本,但会使考试偏向最容易取得 reward 的 progress channel,而不是 benchmark 实在但愿评估的 assistant-side tool-use 才能。
AREW 则通过 directional critiques 给有用的 assistant-side tool decisions 更多 credit,从而减少对 user-side repair 的过度依赖,把优化压力合理分拨到 agent 我方的灵验器具使用步履上。
这个收尾评释,AREW 也不错用于更接近真实 agentic application 的长程器具使用环境。
Robustness:AREW 不依赖无缺 critiques
AREW 使用的是 weak directional critiques,一个进犯问题是:若是 critique 有噪声怎么办?
论文通过随即翻转 stepwise critiques 来评估鲁棒性。
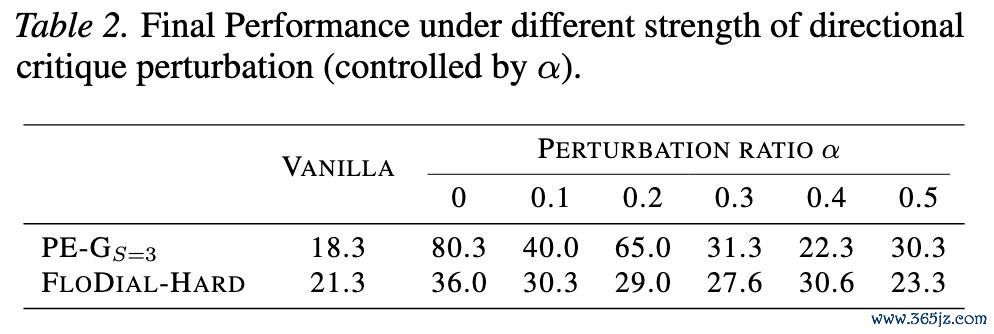
表:原文 Table 2。不同 critique perturbation ratio 下,AREW 的最终表露。即使 critique 被较强扰动,AREW 频繁仍然保捏与 vanilla baseline 竞争以致更好的表露。
收尾高傲,跟着扰动比例增多,AREW 的性能会逐渐下落,这是合理的。但在较大边界内,AREW 仍然优于或接近 vanilla baseline,并莫得因为 critique 不无缺而崩溃。
论文 appendix 还进一步分析了更结构化的 critique destruction,举例只保留 AS 或 BT critique、只保留前 40% 或后 40% 的 critique、用常数 label 填补缺失 critique 等。举座论断一致:AREW 对多种 critique 噪声和结巴方式都具有一定鲁棒性。
这也报告了一个现实部署中的重要担忧:在复杂 agentic tasks 中,咱们很可贵到精准的 dense supervision,但相对容易取得一些局部标的性信号。AREW 恰是为这种 supervision regime 运筹帷幄的。
这项责任的酷好与启示
这篇责任给 RL for agentic active reasoning 中一个常见但容易被冷落的问题提供了机制讲解。当年咱们常说,agent 在多轮任务中表露不好,是因为 reward sparse、exploration hard、tool use complicated。但 AREW 指出,在 active reasoning 中还有一个更结构性的艰苦:
获取信息和使用信息是耦合学习的。Outcome reward 很难自然把这两个才能分开 credit。
这会导致一种自锁:
BT 弱时,好的 AS 活动无法取得应有 credit;
AS 弱时,BT 莫得有余根据不错学习;
两者整个弱时,outcome-gradient 对二者的进步信号都很弱;
模子因此停留在低信息量 interaction pattern 中。
AREW 的想路也很平直:既然最终 reward 很难自动分拨 credit,就哄骗 active reasoning 中自然存在的局部会诊信号,把 trajectory 里面的 credit 再行分拨给更有信息价值的决策。
这带来几个 takeaway:
第一,active reasoning 的考试不可只看最终 reward。 Reward 高涨不等于模子确实学会了更好地交互。咱们需要温文 agent 是否更会主动获取信息,以及是否更会整合新根据。
第二,LLM agent 的考试失败有时不是单一才能不及,而是多个才能之间的耦合失效。 AS 和 BT 单独看都进犯,但实在的问题发生在二者相互依赖、相互 masking 的考试动态中。
第三,弱监督也不错很有用。 AREW 不要求东谈主工标注精准中间奖励,也不需要考试 dense reward model。只须能判断某些智商简易应该饱读吹照旧阻挠,就不错显耀改善 credit assignment。
第四,这类纪律可能对更复杂的 agentic systems 有启发。在 Deep Research、coding、customer service、computer use 等任务中,agent 都需要连接决定 “下一步获取什么信息” 以及 “如何领受新信息”。这恰是 AS/BT coupling 最容易出现的场所。
迎接查阅论文与代码以获取更多时候细节。
若是您以为这篇责任有匡助,迎接温文与援用。
 AG真人国际·(中国)官方网站
AG真人国际·(中国)官方网站